

Representation Learning: Learning Features for Feature Extractors
Contents
1. Introduction
Representation Learning is a technique that enables models to automatically learn important features from raw data. This process usually relies on a feature extractor that transforms input data into latent vectors containing core information.
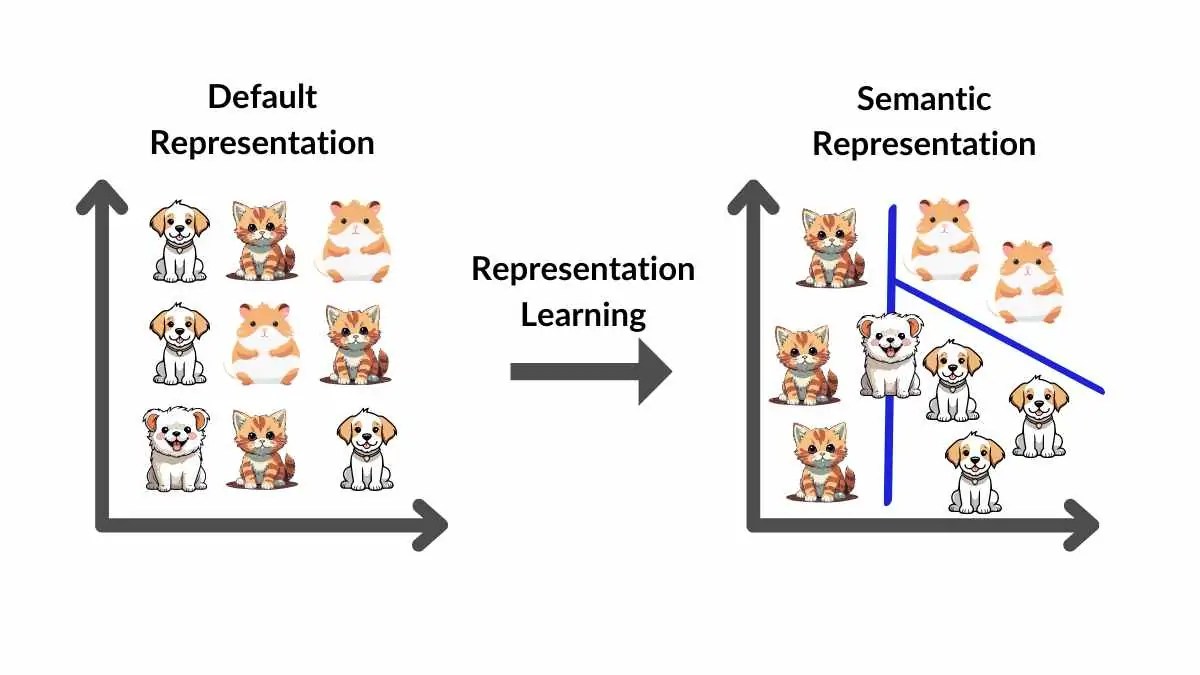 Illustration of representation learning process: input → model → latent vector
Illustration of representation learning process: input → model → latent vector
These latent vectors can be reused for various tasks such as classification, detection, or others, saving training time and improving overall efficiency.
2. Concept of Representation Learning
Representation Learning is the process of learning data representations that preserve important information while filtering out noise.
The feature extractor is the main component that converts input data into numerical latent vectors — compact, generalized representations that serve as the foundation for downstream tasks.
3. Applications of Representation Learning
- Reusing learned representations for multiple tasks (multi-task learning).
- Pretraining to improve performance when labeled data is limited.
- Widely used in fields like image processing, audio, natural language processing, and more.
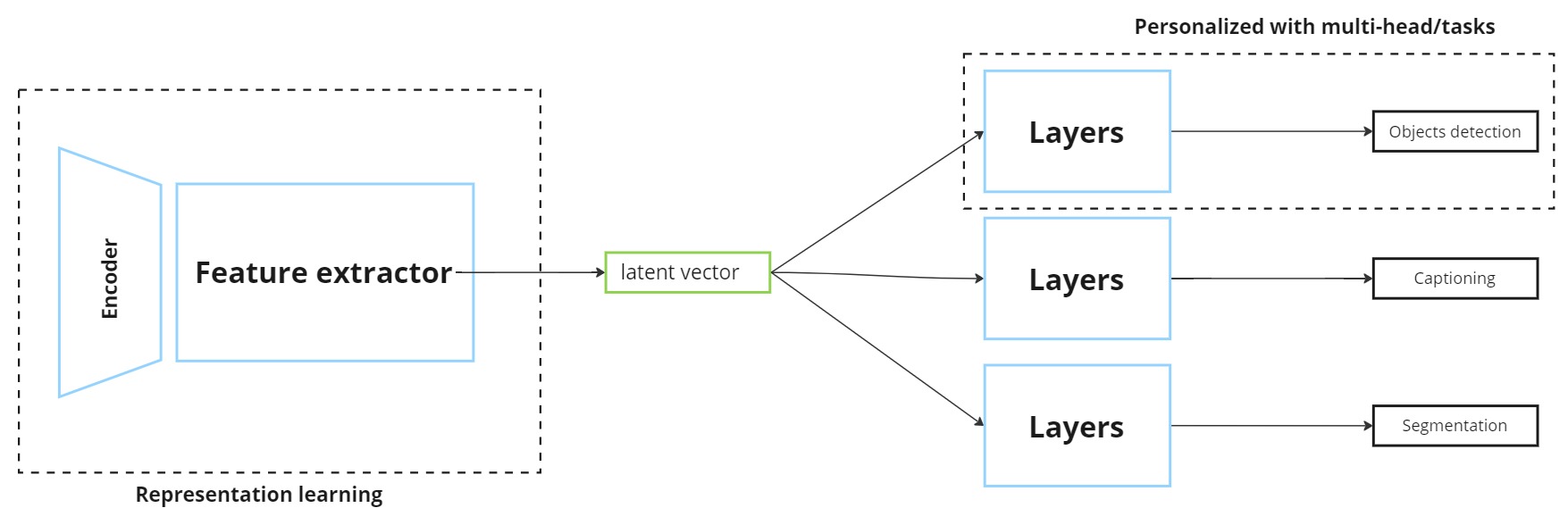 Shared representations applied across different tasks
Shared representations applied across different tasks